By using the most advanced data parallelization technologies, we reduced our Radiology AI algorithm training time from days to 3 hours
Motivation
At Aidoc, we use deep learning to detect abnormalities in radiology scans, helping doctors improve the standard of care in clinics and hospitals around the world. Deep learning is a highly empirical field, and as we always strive towards higher and higher accuracies, the AI team needs to rapidly prototype, revise, and evaluate hundreds of research directions. Prior to the work presented in this blog post, a single experiment could take up to 100 hours running on a single machine. To make this research process faster and more agile, we turned to new technologies and advancements in distributed computation. Using up to eight powerful GPUs running in parallel enabled us to complete each experiment within 3 hours, or less if an even higher number are employed.
The first step in this journey was to use Tensorflow’s native data parallelization to divide the work of passing images forwards and backward through the graph. We found, however, that larger numbers of workers required complex restructuring and code addition, for example, to accommodate parameter servers. Furthermore, the marginal improvement with each additional GPU dropped rapidly after a certain threshold. As demonstrated in a recent publication by Uber’s Machine Learning Team, at 128 GPUs TensorFlow’s native distribution scaling efficiency drops to 50% compared to a single worker.
As a result, we turned to Horovod, an open-source library published by Uber that works on top of Keras and Tensorflow, to more efficiently implement our data parallelization. Horovod provides a user-friendly interface for utilizing the most advanced and recent insights in deep learning parallelization, based on academic papers such as Facebook’s Large Minibatch SGD: Training ImageNet in 1 Hour. Underlying Horovod is NCCL-implemented ring-all reduce, a parameter-server-free method of inter-node communication published by Baidu. Each worker communicates only with its neighbors to share and reduce gradients. Encouraged by the elegance of the concept and Uber’s promising results, we proceeded to implement Horovod into our training pipeline.
Since we use MissingLink’s experiment deployment system to transparently run experiments on the cloud, we also configured Docker support for Horovod (installed Docker, NVIDIA-Docker, and adapted Horovod’s Dockerfile into our existing Dockerfile). It was relatively straightforward to mount our data directories and start running Aidoc code through Horovod with Docker.
POC (Proof-of-Concept) Experiments
In the rest of this blog post, we present the results of a set of POC experiments we conducted to assess Horovod’s efficacy in our use case.
We started by using a small subset of Aidoc’s database, consisting of 5000 training and 1000 validation images. We trained an Aidoc proprietary convolutional neural network architecture for 18 epochs using various numbers of workers and types of GPU.
Our Horovod experiments are configured in accordance with the Running Horovod documentation, in which each process is pinned to exactly one GPU. Our distributed Tensorflow experiments are run using code adapted from Keras’s multi-gpu-utils, in which each GPU is fed images and the gradients are averaged on the CPU at the end of each batch. Horovod replicates this behavior but uses NCCL’s ring all-reduce to optimize performance.
Learning Rate and Warmup
For our Horovod experiments, we adhered to the linear scaling rule, which stipulates that the effective learning rate be multiplied by the number of workers at the beginning of training. As expected, this heuristic breaks down during the earlier epochs, when the network’s weights are changing rapidly. Indeed, we observe that losses for the earlier epochs differ considerably when the number of workers is high (Figure 1). We mitigated this effect using the linear learning rate warmup strategy recommended by Goyal et al. in Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour (refer to Equations 3, 4) through the Horovod-implemented Keras callback. Even with the warmup, we expect some initial discrepancies in the loss curves (early stage, network learning quickly). However, we observe that these loss curves converge as training continues, strongly suggesting that accuracy is uncompromised if training is allowed to continue for a sufficient number of epochs. Given how much more quickly a high number of workers can finish a single epoch, this is ultimately a more than worthwhile tradeoff.
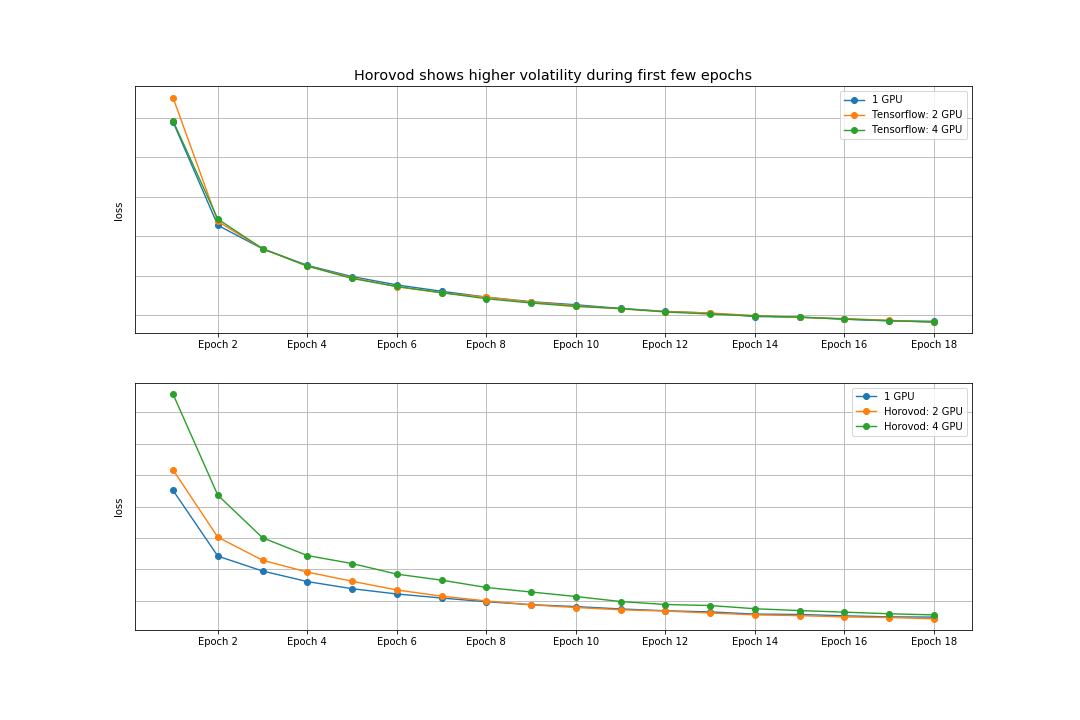
Results
Scaling effiencyis calculated with the single GPU as the normalizing factor, i.e. 100% scaling for N GPUs means the number of epochs per hour was multiplied by N. 90% scaling for N GPUs means the number of epochs per hour was multiplied by 90% x N.
Preliminary Experiments with Horovod on V100 GPUs (on AWS)
With the V100s, the machine’s ability to process images began to outstrip the rate at which it can generate new images. We compensated by increasing the read speed of the data volumes, thus keeping the data buffer full. Despite these unknown bottlenecks, we found that 4 V100 GPUs can complete the 18-epochs training in a single hour, a process that had previously taken nearly half a day on a single GPU.
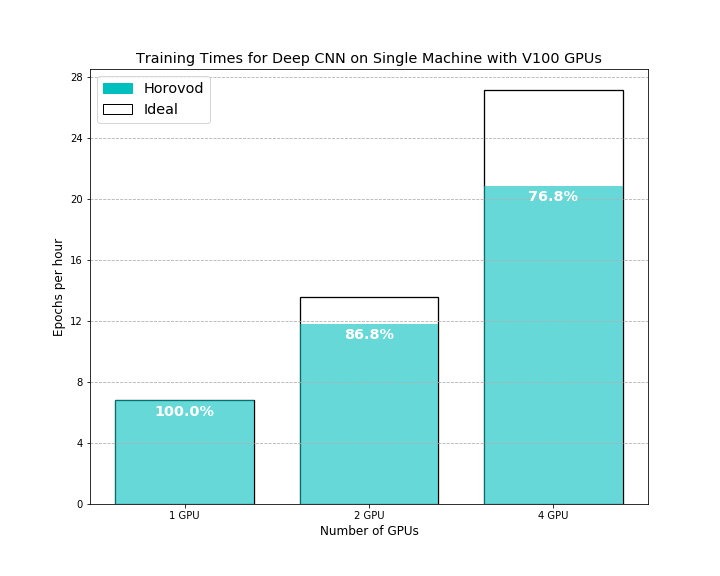
Horovod’s paper shows that their training speed (metric of image/sec) retains close to 100% efficiency for 8 GPUs and close to 90% for 16 GPUs. As discussed above, the results above demonstrated to us that other bottlenecks in our model and data I/O infrastructure could be optimized for parallelization, and we indeed solved many of these challenges in later stages of our work and reproduced the results from the Horovod paper.
Further Scalability
Currently, we run our experiments on 4-16 GPUs depending on the project and our need.
In the future, as we further scale the size of our datasets, we will explore scaling to networks with a much larger number of nodes. Anecdotally, we observed that Horovod performs comparably for the same number of workers even when MPI is forced to use a networked connection. This, in addition to the relative ease of configuring networked Horovod compared to Tensorflow’s distributed API, makes us optimistic about multi-node training with Horovod.
Summary and Next Steps
Today, distributed training is an integral part of Aidoc’s research infrastructure. It has enabled a paradigm shift in the research process, where several research iterations which previously would have taken weeks due to the training times can now be completed in a single day.
Making this capability reality was hard work – integrating the “off-the-shelf” Horovod library (which is by far the best solution available) took more than a month of work. Even once it was functional, there still remained many loose ends, such as discovering and addressing new bottlenecks (such as IO slowdowns) and adapting the model and training infrastructure to behave optimally under parallelization. This multi-disciplinary process synthesized Aidoc’s expertise in deep learning research, deep learning infrastructure engineering, and DevOps.






